
Par Clair-Yves, Développeur Data chez WEENEO
La gestion de base de données se fait habituellement par l’utilisation d’un langage de programmation déclaratif appelé SQL (pour Structured Query Language). Ce langage permet de gérer des grandes quantités de données rapidement et avec précision mais sa prise en main peut paraître un peu abstraite.
Dans cet article, nous allons voir comment gérer efficacement une hiérarchie de nœuds en SQL, en comparant une approche classique avec une méthode beaucoup plus performante : le modèle des Nested Sets (ensembles imbriqués).
Pourquoi gérer une hiérarchie en SQL ?
Dans de nombreux projets data ou applicatifs, il est nécessaire de gérer des structures arborescentes :
-
Catégories de produits e-commerce
-
Organigrammes d’entreprise
-
Systèmes de fichiers…
Dans mon cas, en tant que développeur data, je dois manipuler un système hiérarchique de type parent/enfants permettant de gérer un mécanisme d’héritage.
Un enfant possède un seul parent, tandis qu’un parent peut avoir plusieurs enfants. Il est donc essentiel de pouvoir :
-
🔎 Retrouver tous les descendants d’un nœud
-
⬆️ Retrouver tous les ascendants d’un nœud
-
⚡ Le faire rapidement, même avec un grand volume de données
Approche classique : la relation parent/enfant
Pour cela il est nécessaire de pouvoir retrouver facilement et efficacement l’ensemble de la “généalogie” d’un nœud, en descendant (enfants) ou en remontant (parents). Cette information peut être enregistrée pour chaque nœud dans une table basique comme celle-ci :
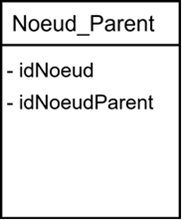

Une première entrée, appelée ’root’ ou racine de la table, aura idNoeud = 1 et pour parent lui-même (=1).
Cette solution fonctionne mais elle est très limitée en termes de performance. Pour avoir l’ensemble des enfants d’un nœud il faudra récursivement parcourir l’ensemble des entrées plusieurs fois pour récupérer les nœuds qui mènent à l’idNoeud désiré (de même pour l’ensemble des parents d’un nœud).
Résultat :
-
❌ Temps de lecture élevé
-
❌ Mauvaises performances sur de grands volumes
-
❌ Requêtes plus complexes
Solution performante : le modèle des Nested Sets en SQL
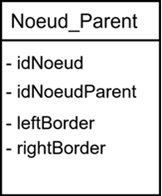
On peut faire beaucoup mieux en définissant deux nouveaux champs : le bord gauche et le bord droit. Ces deux champs forment un intervalle [leftBorder, rightBorder] dans lequel doit tenir l’ensemble des bords (gauche et droit) de toute la descendance d’un nœud.
Règle fondamentale
👉 Tous les descendants d’un nœud sont contenus dans son intervalle.
👉 Les valeurs de bordures sont uniques (aucun doublon).
Il paraît qu’une image vaut mille mots donc même si je ne suis pas doué en dessin :
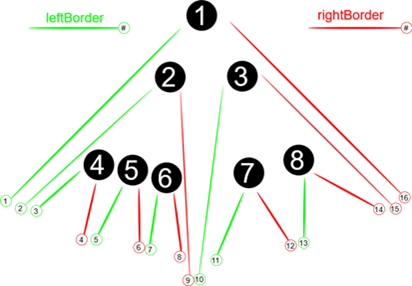
Ce système permet d’avoir l’ensemble des descendants d’un nœud en une recherche non récursive (unique index scan), il suffit de sélectionner les nœuds dont les bords sont inclus dans ceux du nœud parent :
Select children.*
from Nœud_Parent n
inner join Nœud_Parent children on n.leftBorder < children.leftBorder
and n.rightBorder > children.rightBorder
where n.idNoeud = {id du nom parent} ;
Exemple : Dans notre schéma, la descendance du nœud 2 sont les nœuds dont les bords sont contenus entre 2 et 9 (soient les nœuds 4,5 et 6).
Pour obtenir l’inverse (l’ascendance d’un nœud), il suffit dans la requête précédente d’inverser les ‘>’ et les ‘<’. C’est pas beau ça ?
L’énorme avantage de cette méthode :
✅ Une seule requête
✅ Pas de récursion
✅ Index scan efficace
Améliorations du modèle hiérarchique
- Idéalement on ajoutera aussi un autre champ, la profondeur, qui permettra de savoir au sein d’une descendance à quel niveau se situent les différents nœuds.
Dans notre schéma, la racine (nœud 1) a une profondeur de 1 ; les nœuds 2 et 3 une profondeur de 2 et le reste une profondeur de 3. - En ajoutant un dernier champ, idArbre, on pourra avoir plusieurs de ces hiérarchies (ou arbre généalogique si on veut) en parallèle, toutes enregistrées dans la même table. De quoi stocker toute un forêt de nœuds interconnectés et facile à exploiter.

Conclusion : optimiser les hiérarchies SQL intelligemment
La gestion de hiérarchies en SQL peut rapidement devenir un goulet d’étranglement en performance.
Le modèle des Nested Sets offre une solution efficace pour les lectures intensives, au prix d’une complexité accrue lors des modifications. Il faut en effet décaler les bords de tous les nœuds« situés à droite » d’un nouveau nœud et inversement en cas de suppression.
Comme souvent en base de données : il n’existe pas de solution universelle, seulement des compromis adaptés à votre cas d’usage.
Cette solution est recommandée dans le cas où la structure de la hiérarchie n’est pas amenée à évoluer beaucoup relativement au nombre de lecture de cette table.