
Définition du Data Mining
Le Data Mining, également connu sous le nom de fouille de données, est un processus d’exploration et d’analyse des données volumineuses afin de découvrir des modèles significatifs, des relations ou des tendances cachées. Cette discipline trouve son utilité dans divers domaines tels que le commerce, la finance, la santé, la science et bien d’autres. L’objectif principal du Data Mining est d’extraire des informations exploitables à partir de grands ensembles de données, souvent complexes et non structurés.
Les autres noms français donnés au Data Mining :
- Exploration de données
- Forage de données
- Extraction de connaissances à partir de données
Les différentes techniques de Data Mining
L’exploration et l’analyse de données en Data Mining impliquent l’utilisation de diverses techniques pour extraire des informations pertinentes et des modèles significatifs à partir des ensembles de données. Voici un aperçu des principales techniques utilisées dans le processus de Data Mining :
Le nettoyage et la préparation des données
Avant d’appliquer des techniques de Data Mining, il est crucial de nettoyer et de préparer les données. Cela implique le traitement des valeurs manquantes, la normalisation des données, la suppression des doublons et la transformation des données non structurées en un format exploitable.
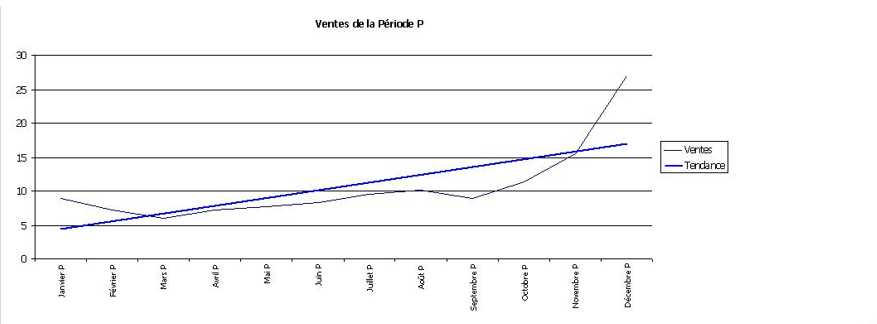
Les modèles de suivi
Les modèles de suivi sont utilisés pour analyser les tendances et les évolutions dans les données au fil du temps. Ces modèles permettent de détecter les variations saisonnières, les cycles et les changements de comportement, ce qui est essentiel pour la prévision et la planification.
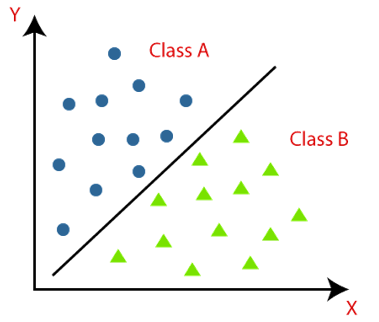
La classification
La classification consiste à attribuer des étiquettes ou des catégories prédéfinies à des objets en fonction de leurs caractéristiques. Cette technique est largement utilisée dans divers domaines tels que la reconnaissance de formes, la détection de spam, la classification des clients, etc.
L’association
L’association est utilisée pour découvrir des relations intéressantes entre les variables dans de grands ensembles de données transactionnelles. Cette technique est couramment utilisée dans le domaine du commerce électronique pour la recommandation de produits et la gestion des paniers d’achat.
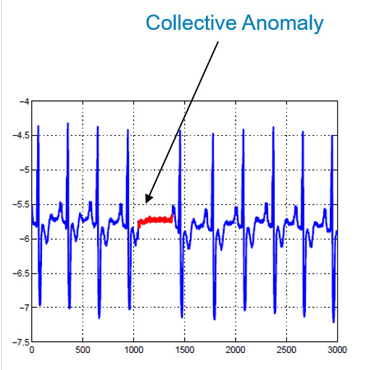
La détection des anomalies
La détection des anomalies vise à identifier des observations inattendues ou aberrantes dans les données. Cette technique est utilisée dans la détection de fraudes, la maintenance prédictive, la surveillance de la sécurité, etc.
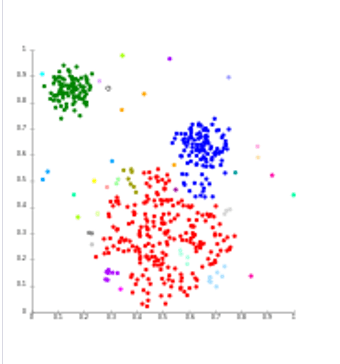
Le regroupement (clustering)
Le regroupement, ou clustering, regroupe les données similaires en clusters ou groupes basés sur leurs caractéristiques communes. Cette méthode est utile pour l’analyse de marché, la segmentation des clients, la recommandation de produits, etc.
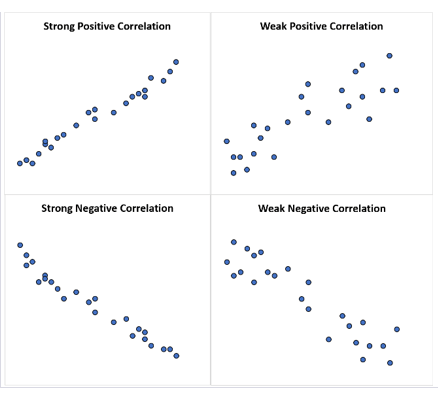
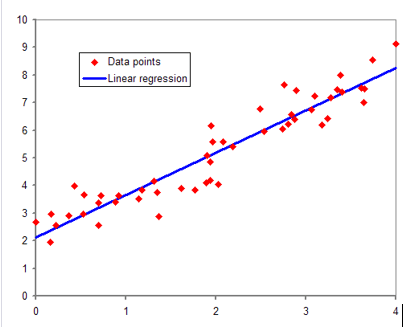
La régression
La régression est utilisée pour analyser la relation entre une variable dépendante et une ou plusieurs variables indépendantes. Elle est largement utilisée dans les domaines de l’économie, des sciences sociales et de la recherche médicale pour prédire des résultats basés sur des données historiques.
La prédiction
La prédiction vise à estimer ou prédire les valeurs futures d’une variable en fonction des données historiques. Cette technique est utilisée dans la prévision des ventes, la modélisation financière, la planification de la demande, etc.
Les modèles séquentiels
Les modèles séquentiels sont utilisés pour analyser des données séquentielles ou chronologiques, telles que les séries temporelles, les données génomiques, les signaux biomédicaux, etc. Ces modèles sont essentiels pour la prévision et la détection de motifs dans les séquences de données.
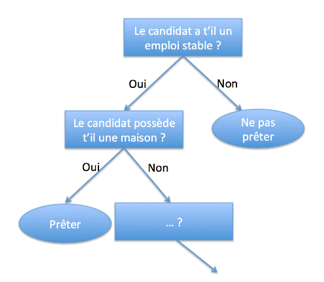
Les arbres de décision
Les arbres de décision sont des modèles de classification ou de régression qui utilisent une structure arborescente pour représenter et évaluer les décisions. Ces modèles sont faciles à interpréter et à visualiser, ce qui en fait des outils précieux pour la prise de décision.
La visualisation
La visualisation des données est une composante essentielle du processus de Data Mining, permettant aux analystes de comprendre et d’explorer les modèles et les tendances dans les données. Des techniques de visualisation telles que les graphiques, les tableaux de bord interactifs et la cartographie sont utilisées pour présenter les résultats de manière intuitive.

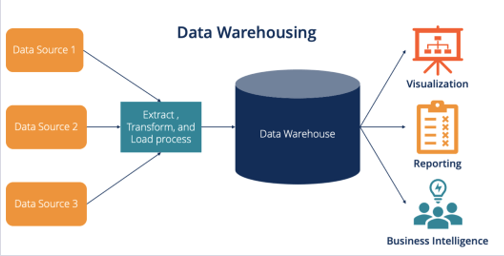
Le data warehousing
Les entrepôts de données, ou data warehouses, sont des systèmes de gestion de bases de données conçus pour stocker et gérer de grandes quantités de données provenant de sources multiples. Ces entrepôts fournissent un accès rapide et efficace aux données pour l’analyse et le reporting.
Le traitement de la mémoire à long terme
Le traitement de la mémoire à long terme, ou LSTM (Long Short-Term Memory), est une technique d’apprentissage profond utilisée dans le traitement des séquences de données. Les LSTM sont particulièrement efficaces pour modéliser les dépendances à long terme dans les séquences temporelles et les données séquentielles.
Le machine learning et l’intelligence artificielle
Le Machine Learning et l’Intelligence Artificielle jouent un rôle crucial dans le domaine du Data Mining, en fournissant des algorithmes et des techniques pour l’analyse et la modélisation des données. Ces domaines en constante évolution offrent de nouvelles possibilités pour extraire des connaissances à partir de données complexes et non structurées.
En combinant ces différentes techniques et en utilisant les bons outils, les professionnels du Data Mining peuvent explorer et exploiter pleinement le potentiel des données pour obtenir des insights précieux et prendre des décisions éclairées.
Outils utilisés pour le Data Mining
Il existe une multitude d’outils pour effectuer des tâches de Data Mining. Voici quelques-uns des outils les plus populaires, chacun offrant ses propres fonctionnalités et avantages :
1. Python
Python est un langage de programmation polyvalent largement utilisé dans le domaine de la Data Science et du Data Mining. Il offre une vaste gamme de bibliothèques et de frameworks tels que Pandas, NumPy, scikit-learn, TensorFlow, etc., qui permettent d’effectuer diverses tâches d’analyse de données, de modélisation et de visualisation.
2. RapidMiner
RapidMiner est une plateforme de Data Science qui propose une interface conviviale pour la préparation des données, la modélisation, l’évaluation et le déploiement des modèles. Il offre une grande variété d’algorithmes de Data Mining et de fonctionnalités de traitement des données, ce qui en fait un choix populaire parmi les professionnels du domaine.
3. Orange
Orange est une suite logicielle open-source qui offre des outils de visualisation de données, de modélisation prédictive et de Data Mining. Il propose une interface graphique intuitive qui permet aux utilisateurs de créer et d’exécuter des workflows de traitement de données sans écrire de code, ce qui le rend accessible aux débutants et aux experts.
4. KNIME
KNIME est une plateforme open-source qui permet aux utilisateurs de créer des workflows visuels pour l’analyse des données et le déploiement de modèles. Il propose une large gamme de modules pour le Data Mining, la manipulation de données, la visualisation et plus encore. KNIME est apprécié pour sa flexibilité et sa capacité à intégrer des outils et des technologies externes.
5. SAS Enterprise Miner
SAS Enterprise Miner est une solution logicielle robuste conçue pour l’analyse prédictive et le Data Mining. Il offre une large gamme d’algorithmes de modélisation avancés, une interface conviviale pour la création de workflows et des fonctionnalités de déploiement de modèles. SAS Enterprise Miner est largement utilisé dans les entreprises pour résoudre des problèmes complexes liés à l’analyse de données.
6. Rstudio
Rstudio est un environnement de développement intégré (IDE) pour le langage de programmation R, largement utilisé dans l’analyse de données et le Data Mining. Il offre une interface conviviale pour l’importation, la manipulation, l’analyse et la visualisation des données, ainsi que pour l’exécution de modèles de Machine Learning. Rstudio est apprécié pour sa robustesse, sa flexibilité et sa communauté active de développeurs et d’utilisateurs.
Ces outils offrent aux professionnels du Data Mining une gamme de fonctionnalités et de possibilités pour explorer, analyser et exploiter pleinement le potentiel des données. Le choix de l’outil dépend souvent des besoins spécifiques du projet, des préférences personnelles et de la familiarité avec la technologie.
Conclusion
Le Data Mining est une méthode utilisée dans toutes les Data-Driven entreprises. Il est primordiale pour comprendre et traiter la donnée. Il est appliqué à l’aide de divers logiciels et langages et se représente de différentes manières à des fins de création et d’amélioration.
Il aide les entreprises à optimiser leur avenir. Il permet de comprendre le passé et le présent et de faire des prédictions précises sur ce qui est susceptible d’arriver.
Le Data Mining est utilisé pour répondre à des objectifs business/commerciaux comme :
- Augmenter ses revenus
- Mieux comprendre les segments de clientèle et leurs préférences
- Acquérir de nouveaux clients
- Fidéliser les clients et augmenter le taux de rétention (fidélité)
- Détecter une fraude
- Identifier les risques
- Suivre les performances opérationnelles
Grâce à cette technologie, les décisions sont basées sur une véritable BI, plutôt que sur des intuitions ou instincts, ce qui permet d’obtenir des résultats cohérents et de prendre ou conserver une avance sur votre concurrence.
Ces contenus vont vous intéresser :